google Assistant NLP팀의 computational linguist이신 박지호님의 위클리 NLP(week 3, week 4)를 토대로 공부한 내용이다.
jiho-ml
구글 컴퓨터 언어학자가 쓰는 머신 러닝, 자연어 처리 (NLP), 딥러닝 (deep learning) 블로그
jiho-ml.com
용어 정리
neural network 인공 신경망
자연어 처리 Natural Language Processing (NLP)
(week3)//vector
scalar(크기) + 방향 = vector
vector는 n차원의 공간을 갖는 존재=> euclidean space
euclidean space : 고대 수학자 유클리드가 연구한 평면과 공간을 일반화한 것으로 임의 차원의 공간으로 확장한 것
(week4) //word embedding, GloVe, word2vec
단어간의 관계를 학습해 vector에 저장하는 word embedding(word vector)
one-hot vector (Nx1 column vector)
몇 천~ 몇 만 차원이 요구되며, 단어표기에 있어서 1개의 row를 제외하고 모두 0이므로(sparse) 비효율적임
wordvector
몇 십~ 몇 백 차원으로 낮추는 것을 목표로, 내부의 모든 row가 0이 아닌 real number(실수)로 구성
unsupervised learning(비지도학습)은 untagged하게 pattern을 읽어 학습하는 방식.
동일 맥락에서 발생하는 단어는 의미가 유사하다는 distributional hypothesis(분포 가설)을 machine learning에 활용시킨 예시 => stanford의 GloVe, Google의 word2vec
GloVe
같은 문장에 한 단어가 근처 어떤 단어와 몇 번 같이 나오는지 세는 것(co-occurrence matrix)
corpus에 N개의 단어가 존재한다면
1. N x N matrix 생성 및 0으로 초기화
2. 해당 영역 1씩 증가 => 해당열의 단어와 다른 모든 단어간의 빈도수 통계를 확인 가능
+) dimensionality reduction으로 차원 축소 가능(sparse matrix해결)
Ex) 40000 x 40000 -> 300 x 40000
각 열 (300x1)이 하나의 단어를 대표하게 됨, 40000개에서 300개 숫자로 압축
N의 크기가 큰 경우 matrix의 크기가 지나치게 큰 문제가능성 해결,
0이 많은 sparse matrix의 문제가능성 해결
GloVe는 Single Value Decomposition (SVD) 사용
+) 고유값분해, 특이값분해, 주성분분석
eigendecomposition, eigenvector Decomposition (EVD) 고유값분해
고유값 분해 : 행렬A를 eigenvector와 eigenvalue으로 분해한 것
*모든 대칭행렬은 고유값 분해가 가능하다.
선형 변환A(정방 행렬)에 의한 변환 결과가 자기 자신의 상수 배가 되는 0이 아닌 벡터 ->고유벡터(eigenvector)
상수배 값-> 고유값(eigenvalue)
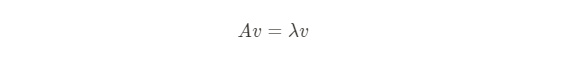
*성형변환 이후에도 V의 방향변화가 없으며, 크기만이 변화함
Single Value Decomposition (SVD) 특이값분해
모든 m*n행렬에 대해 적용가능(square matrix, 즉 정방행렬의 여부와 관계없다는 측면이 고유값 분해와 차별됨)
Principle Component Analysis(PCA) 주성분분석
기본적으로 eigenvector를 사용하므로 n by n 행렬만으로 이뤄진 square matrix만을 사용한다.
분포된 Data의 주성분(Principal Component, 해당 방향으로 데이터의 분산이 가장 큰 방향벡터)를 찾는 방법
선형 연관성이 있는 고차원의 data를 주성분에 해당하는 저차원의 data로 변환시키기 위해 직교변환을 사용한다.
word2vec
continious bag-of-words(CBoW) or skipgram알고리즘으로 학습
- continious bag-of-words(CBoW) : 주변단어를 모두 합쳐본 후, 타깃 단어 맞추는 방식
- skipgram : 타깃단어를 보고 주변단어 맞추는 방식
예측을 위한 classificaiton model은 neural network로 구현되고 stochastic gradient descent(SGD)로 학습됨
input은 Nx1 word embedding으로 들어가며, 처음에는 random한 숫자로 embedding이 초기화되지만 학습이 진행될 수록 word embedding에는 주변단어와의 관계에 대한 정보가 encoding된다.
+)인공신경망, 확률적 경사하강법
artificial neural network, ANN 인공신경망
인공 뉴런(노드)가 학습을 통해 시냅스의 결합세기를 변화시켜며 문제 해결 능력을 갖는 모델
계층형 신경망(Feed-Forward Neural Netrwork, FNN), 순환 신경망(Recurrent Neural Network, RNN), 컨볼루셔널 신경망(Convolutional Neural Network, ConvNet, CNN)이 존재한다.
stochastic gradient descent(SGD) 확률적 경사 하강법
전체 데이터가 아닌 일부 data의 모음을 사용하여 경사하강법을 측정하는 방법으로, 전체 data를 계산하는 Batch Gradient Descent와 비교하여 계산량이 적다. 따라서 상대적으로 부정확할 수 있지만 빠른 속도를 지녔다.
단어 -> word2vec or glove로 학습-> word embedding -> N차원의 vector
추가적으로, vector에 있는 단어는 +,-를 통해 semantics(의미적 관계)와 syntacic(문법적 관계)를 알 수 있다.
'NLP' 카테고리의 다른 글
| [weekly-NLP]7 (0) | 2022.06.04 |
|---|---|
| [weekly-NLP]6 (0) | 2022.06.04 |
| [weekly-NLP]8 (0) | 2022.05.29 |
| [weekly-NLP]5 (0) | 2022.05.11 |
